Prometheus 以强大的功能和灵活的查询语言使其成为了云原生监控领域的佼佼者,本文将分五章节介绍如何快速搭建 Prometheus 监控体系:
- 指标生产
- 抓取配置
- PromQL 查询
- 指标可视化
- 告警
本文只会对关键环节进行介绍不会花费太多篇幅在细节上,虽然大多数情况下 Prometheus 会部署在 Kubernetes 集群中,但为了降低学习门槛本文将使用 Docker Compose 进行部署,完整的部署文件放在 GitHub,准备好 Docker Compose,我们开始吧!
0. 指标生产
指标(Metric) 是 Prometheus 体系中最核心的概念,整个体系都围绕着指标展开,来看一条指标示例:
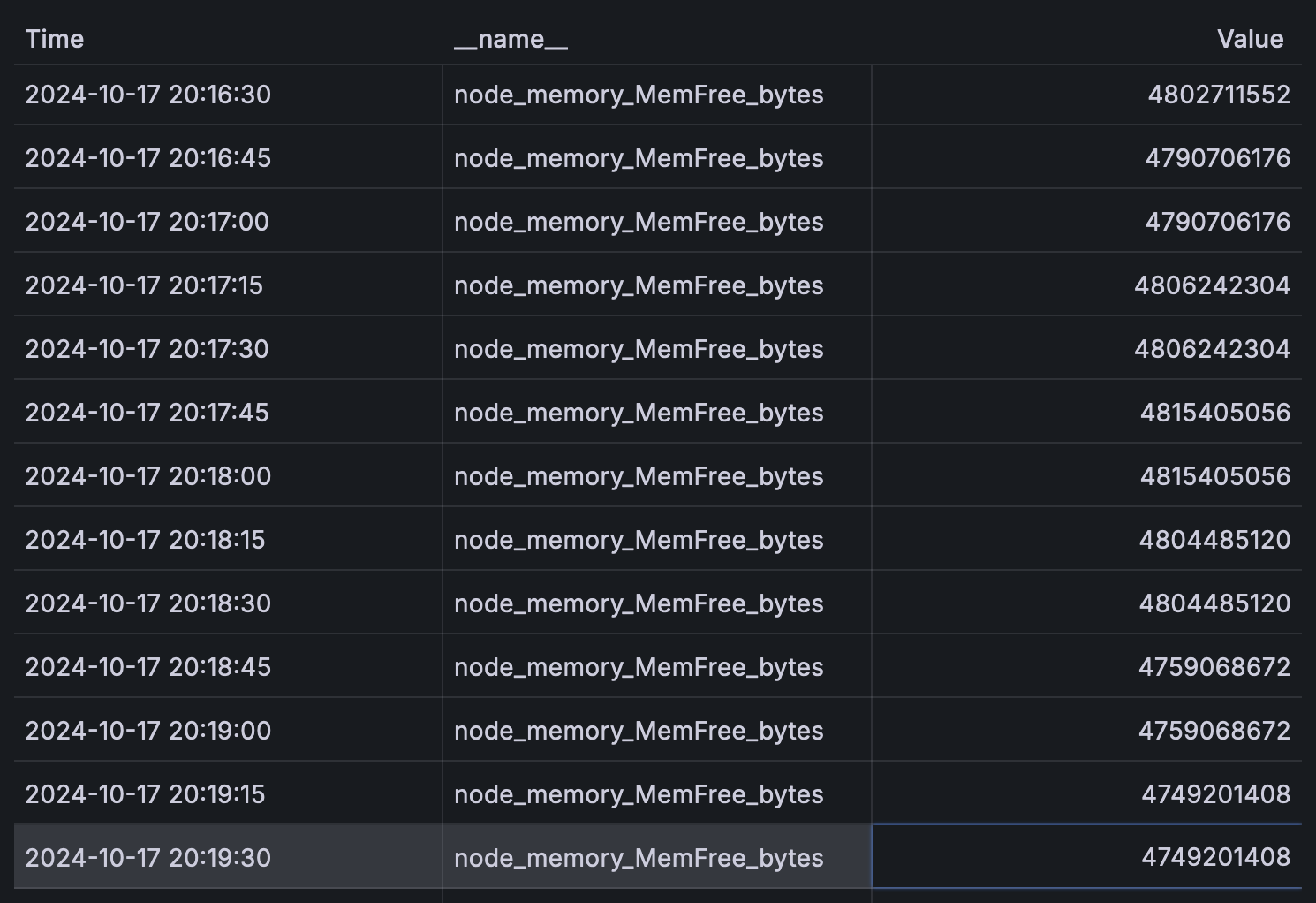
1 | node_memory_MemFree_bytes{instance="172.30.105.137:9100"} 6270644224 |
指标由指标名称和一组键值对标签组成,每个指标可以附加多个键值对形式的标签,这些标签用于提供额外的上下文信息,例如这条指标表示的是实例 172.30.105.137 上的可用内存量,数字 6270644224 是指标的 样本值,表示的是在 某个时间点 上该指标的确切值。
节点的可用内存量会随时间变化,因此指标的值并不是一个固定的值,而是由时间戳和值组成的 时间序列,如图所示:
Prometheus 会定期拉取(Pull)数据存储在时间序列数据库(TSDB)中,数据来源有两种:一种是业务代码中埋点生成的指标,另一种是通过 Exporter 从外部系统获取的指标。下面来看如何在业务代码中埋点生成指标,Prometheus 官方以及开源社区为大多数编程语言都提供了 client library 以便我们集成在业务中。
下面以 Go 语言为例演示如何使用 github.com/prometheus/client_golang/prometheus 包在一个 HTTP 应用中埋点:
1 | const MetricNamespace = "app" |
业务埋点分总体为三个步骤:指标定义、指标更新、暴露指标。示例应用使用了三个不同的方法定义指标,这是因为指标有 类型 的概念:
Counter 类型用于计数器场景,它的特点是只能增加不能减少,适用于请求次数、访问量等计数场景。Counter 的图像是一条上升线:
Gauge 类型用于记录瞬时值,它的值可以随意变化,适用于节点内存可用量、当前在线用户数等会随时变化的场景。Gauge 的图像是一条波动的线:
Histogram 类型用于记录样本值的分布情况,适用于统计请求耗时、响应大小等场景。在定义 Histogram 指标时需要指定桶(Bucket),比如 [0.01, 0.025, 0.05, 0.1, 0.15, 0.2],这些值表示我们希望统计的样本值范围,Histogram 会将收集到的样本值计入对应的桶中,例如
0.021会被计入0.025桶中,0.08则会被计入到0.1桶中,当样本值超出最大桶值时会被计入+Inf桶中。多数情况下 Histogram 会被用于统计 P99、P95 等百分位数:
了解完指标分类后我们再来看示例应用的指标定义,不同类型的指标适用于不同场景,因此埋点的方式也不一样:
requestCounter记录完成的请求数,在请求结束时递增,Counter 类型;inflightRequests记录当前正在处理的请求数,在请求开始是递增,在请求结束时递减,Gauge 类型;requestDuration记录请求耗时分布情况,在请求结束时记录本次请求耗时,Histogram 类型;
为了更好的区分指标还可以在指标上附加标签,在示例应用中我们给所有指标都加上了 method 标签以便区分不同 HTTP 请求方法的数据,但需要注意的是不要选择区分度过高的值作为标签,如:用户 ID、客户端 IP 地址等。对于 Prometheus 来说,只有指标名相同且标签(值)完全相同的指标序列才会被认为是同一个指标序列,过多的标签值会导致指标序列数量暴增,导致 Prometheus 占用大量内存甚至崩溃。接下来我们启动示例应用并发起请求:
1 | docker-compose up app -d |
ab 启动后我们可以通过 curl 命令查看暴露的指标:
1 | curl http://localhost:8000/metrics |
这就是 client library 最终生成的指标数据,以 # 开头的是注释行,除此之外每一行都表示一个指标序列。指标类型似乎没有在输出结果中体现出来,这是因为指标类型只是 client library 用于区分使用场景而设计的,但实际上 Prometheus 并不会记录指标类型,或者说在 Prometheus 中是没有指标类型的概念。
对于 Go 这类常驻内存的语言,业务所产生的指标数据会缓存在内存中等待 Prometheus 抓取,但对于 PHP 这类非常驻语言就无法做到,因为请求结束后解释器实例就会销毁,Prometheus 没有机会抓取数据。对于这类语言一般有两种解决方案:
- 使用 Redis 等外部数据库作为临时指标存储仓库,大多数 client library 都支持这个功能。
- 请求结束后主动将指标数据推送到 PushGateway,PushGateway 会暂存接收到的指标数据等待 Prometheus 抓取。
除了业务系统我们还可能需要对外部系统如 MySQL、Redis 甚至 Linux 系统进行监控,对于这些系统在代码中进行埋点不太现实,幸运的是大部分系统自身都有监控功能,例如 MySQL 中的 Performance Schema,Linux 系统的 /proc 文件系统等。既然无法在代码中埋点那就加一层中间层,把系统自身监控的数据转换成 Prometheus 指标,这就是 Exporter 的概念。常用的系统都能在开源社区里找到对应的 Exporter,例如 node-exporter,用于收集 Linux 系统的状态并生成 Prometheus 指标数据,下面我们启动它:
1 | docker-compose up -d node-exporter |
指标生产环节就介绍到这里,我们已经了解了指标的基本概念以及如何在业务代码中埋点生成指标,接下来我们将介绍如何部署 Prometheus 并使用 PromQL 查询指标数据。
1. Prometheus
Prometheus 是整个体系中的核心组件,负责对指标进行抓取、存储、查询、告警。Prometheus 使用 Go 语言开发,使用 TSDB 存储指标数据,提供了强大的查询语言 PromQL,支持多种服务发现机制,能在各种环境下从目标中抓取指标数据。Prometheus 非常容易部署并且几乎可以「开箱即用」,但有几个关键启动参数需要关注:
--config.file配置文件路径--web.enable-lifecycle允许使用 HTTP API 进行 reload 操作,修改配置后无需重启实例--storage.tsdb.pathTSDB 数据库存储路径--storage.tsdb.retention.timeTSDB 数据保留时间 (默认: 15d)--storage.tsdb.retention.sizeTSDB 数据保留大小
合理设置 retention.time 和 retention.size 参数可以避免 Prometheus 占用过多磁盘空间。下面我们启动 Prometheus:
1 | docker-compose up -d prometheus |
打开浏览器访问 http://127.0.0.1:9090 就可以看到 Prometheus 控制台,在 Expression 输入框输入 app_requests,按下回车键我们就完成了一次 PromQL 查询:
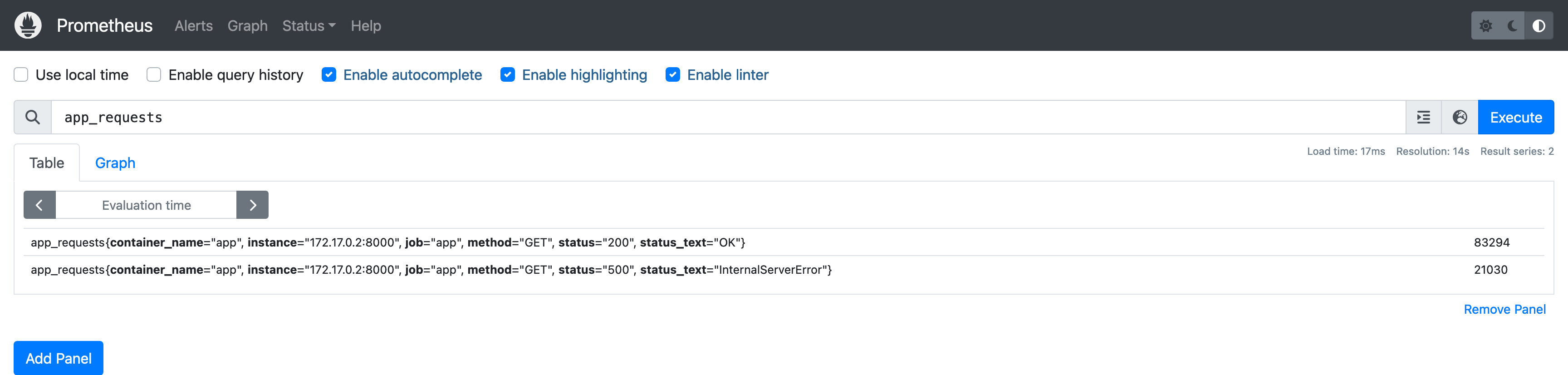
接下来我们来看看 Prometheus 是如何从示例应用中抓取指标数据的,这一切的奥秘都在 prometheus.yml 配置文件中。其中 scrape_configs 字段定义了 Prometheus 的抓取配置,数组内每个元素都代表一个 抓取任务,抓取任务都可以从任意个 抓取目标 中抓取数据,抓取目标可以简单理解为是一个 HTTP Endpoint,因此抓取配置的关键就是告诉 Prometheus 抓取目标在哪里:
1 | scrape_configs: |
配置定义了一个 app 抓取任务,使用静态配置 static_configs 直接指定了抓取目标地址 app:8000,Prometheus 会定期从抓取目标抓取指标数据。
之所以可以使用 app 访问示例应用是因为在 docker-compose 配置中使用 links 字段将 app 容器链接到了 prometheus 容器,prometheus 容器的 /etc/hosts 文件会添加 app 域名和 app 容器 IP 地址的映射。在 Docker 中容器随时会被销毁和重建,重建后的容器 IP 地址必然会发生变化,如果直接使用容器 IP 地址作为 Endpoint,意味着每次容器重建后都需要更新抓取配置的 IP 地址。即便 links 字段能为我们提供一个固定的访问域名,但每次增加新的抓取目标都要修改 docker-compose 配置也是不现实的。因此我们需要一种更高效的方法来「寻找」抓取目标,这就是服务发现 Service Discovery。
服务发现最大的亮点在于它是「发现」目标而不是「指定」目标,我们只需要指定「途径」Prometheus 就会自动发现抓取目标,而这个途径就是一系列以 sd_config 为后缀的配置字段,比如基于 Kubernetes 的 kubernetes_sd_config、基于 Docker 的 docker_sd_config。下面我们使用服务发现方案修改抓取配置:
1 | scrape_configs: |
docker_sd_configs 的配置非常简单,仅仅是指定了 Docker Daemon 的地址,Prometheus 会通过 Docker API 获取 所有容器 并且把它们都作为抓取目标,这就是「发现」的概念。看到这里你可能会产生两个疑问,首先在这个抓取任务中我们只需要抓取 app 容器,但 Docker SD 会把所有容器都当做抓取目标;其次找到 app 容器之后如何把容器 IP 地址以及服务的端口号传递给 Prometheus?
要想回答这两个问题我们需要了解 Relabeling 机制,可以在目标被抓取之前进行 过滤 或者 修改标签。和指标一样抓取目标也有键值对形式的标签,在 Prometheus 控制台 Status -> Service Discovery 页面可以看到所有目标以及目标的标签信息:
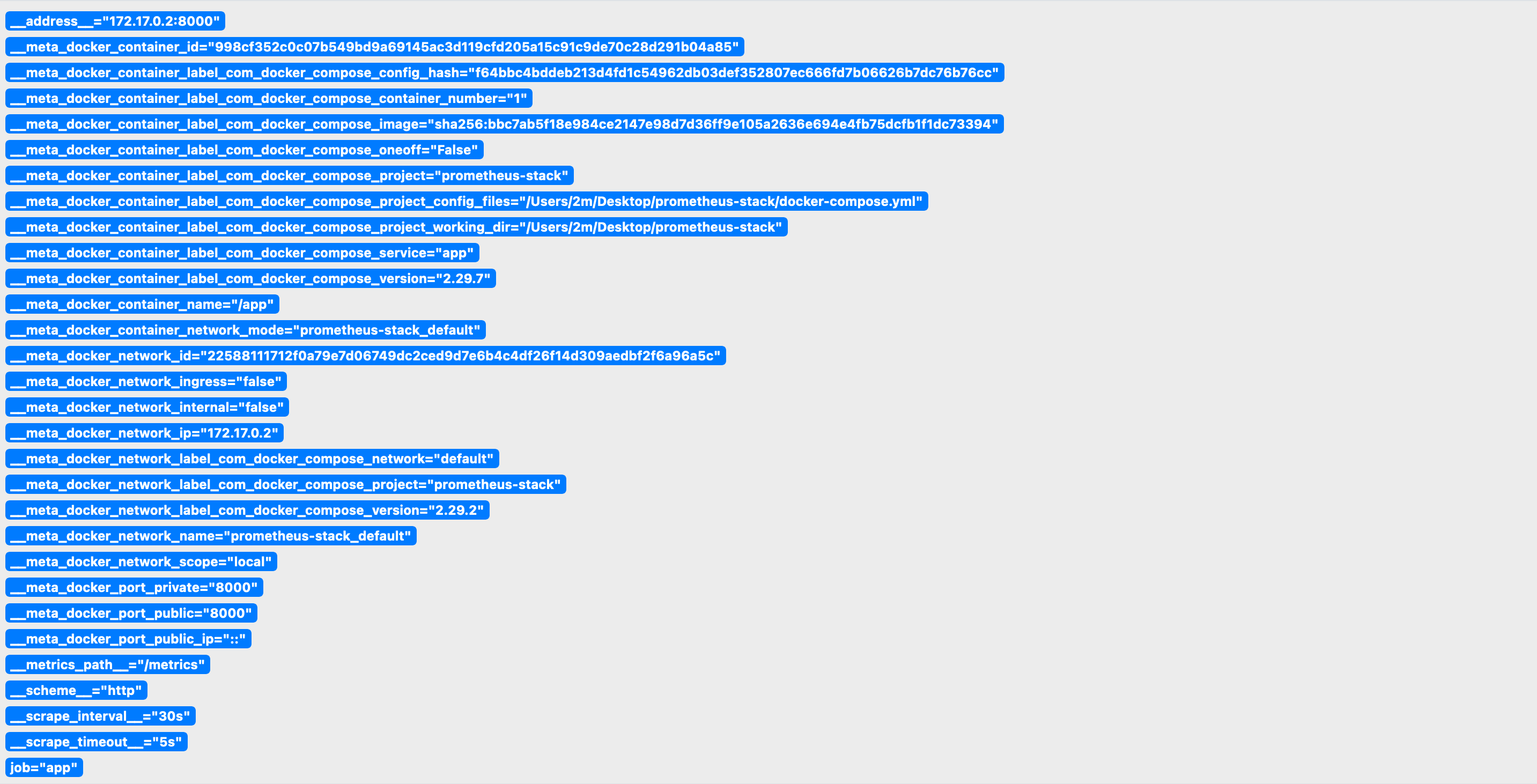
以 __meta_ 为前缀的标签来自于服务发现机制,使用不同的服务发现机制所产生的标签也不同,比如 Docker SD 会把容器名、容器 IP 地址、容器标签等信息附加到抓取目标的标签集合中,这些标签是我们解决问题的关键,因为 Relabeling 机制是基于标签进行操作的,下面我们来看如何解决第一个问题:
1 | - job_name: app |
下面来解释一下这一段 Relabeling 配置的含义,首先是各字段的作用:
source_labels指定源标签,标签值会被用于与regex字段进行匹配以确定 Relabeling 操作是否应用到当前目标separator指定多个标签值的分隔符,默认值为;regex指定正则表达式action指定操作类型,常用的有:keep、drop、replace、labelmap、hashmod、labeldrop、labelkeep、labelreplace
了解完各字段的作用后就能理解这段配置的含义:保留 source_labels 字段所指定的标签值匹配 regex 字段的抓取目标。keep 操作是白名单策略,因此不匹配的抓取目标将会被丢弃。
__meta_docker_container_label_com_docker_compose_project 标签等同于容器的 com.docker.compose.project 标签:
1 | docker inspect --format '{{ json .Config.Labels }}' app | jq |
到这里第一个问题就解决了,此时在 Prometheus 控制台 Status -> Targets 标签页可以看到抓取目标信息:

虽然找到了 app 容器但任务还是 DOWN 状态,从 ERROR 列的错误信息可以看出,Prometheus 尝试使用 HTTP 默认端口抓取数据,而 app 容器监听的是 8000 端口。解决这个问题的方法还是 Relabeling,抓取目标的众多标签中有几个特殊标签,它们的作用是给 Prometheus 提供抓取信息:
__address__抓取目标地址 (IP:Port)__scheme__抓取目标协议,默认:http__metrics_path__抓取目标路径,默认:/metrics
在这个例子中问题出在 __address__ 标签,其它两个标签默认值就是正确的。我们需要将 __address__ 修改为正确的端口:
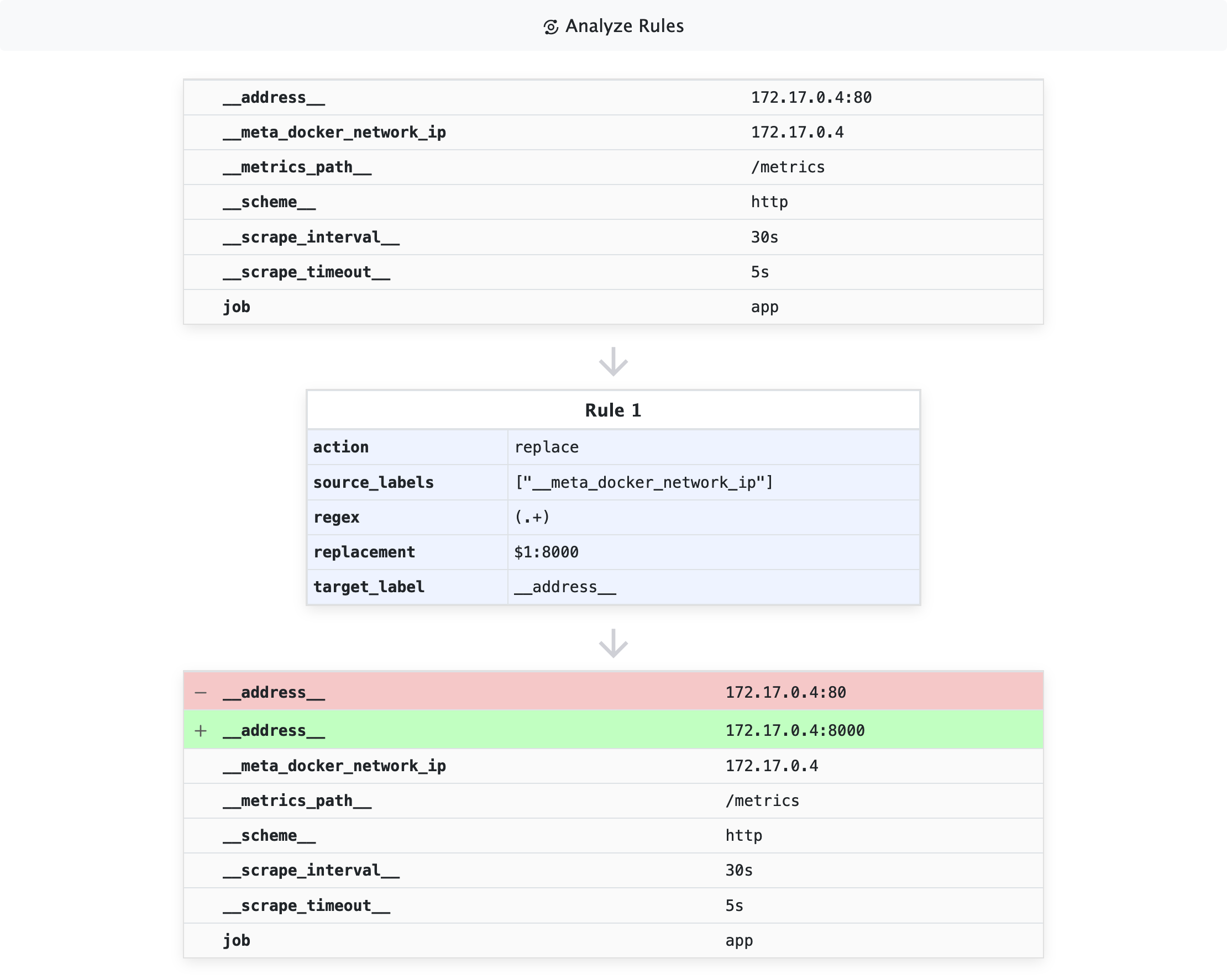
1 | - job_name: app |
这段配置的含义是:将 __address__ 的值替换为 ${__meta_docker_network_ip}:8000。__meta_docker_network_ip 是 Docker SD 提供的容器 IP 标签。
实际上 Docker SD 会尝试通过一些途径找到服务的端口号,例如 Dockerfile 中使用 EXPOSE 指令声明的端口、通过 docker run -p 暴露的端口。如果这些端口号与容器内服务的端口号对应,我们就无需手动修改 __address__ 标签的值。
介绍完对抓取目标的 Relabeling 配置,接下来我们来看看如何对指标序列进行 Relabeling:
1 | - job_name: app |
metric_relabel_configs 字段用于对指标序列进行 Relabeling 操作,注意不要和 relabel_configs 混淆。这段配置的含义是:将 status 标签值为 200 的指标序列的 status_text 标签值替换为 OK;将 status 标签值为 500 的指标序列的 status_text 标签值替换为 Internal Server Error。这样我们就可以在查询结果中看到更直观的状态信息。
下面再来看几种常用的 Relabeling 操作:
- 丢弃指标序列,
__name__是一个特殊标签,它代表指标名称:
1 | metric_relabel_configs: |
- 丢弃指定标签值的指标序列:
1 | metric_relabel_configs: |
- 从指标序列中移除某个标签:
1 | metric_relabel_configs: |
- 将目标信息附加到指标序列,比如将容器名称附加到所有指标序列上,这样就能更好的区分来自不同容器的指标序列。需要注意的是
metric_relabel_configs中无法使用以__meta_开头的标签,因此需要在relabel_configs完成这个操作。
1 | relabel_configs: |
最后推荐一个练习 Relabeling 的网站 Relabeler,它提供了一个可视化的界面帮助你更直观的理解 Relabeling 操作:
2. PromQL
PromQL 是一种简单灵活但功能强大的查询语言,支持多种操作符和函数,能够对指标序列进行聚合、过滤、运算等操作。篇幅所限本文不会对 PromQL 进行深入讲解,仅围绕示例应用的指标进行介绍。
在上文中我们已经尝试了在 Prometheus 控制台执行 PromQL 查询,将查询语句稍作修改:
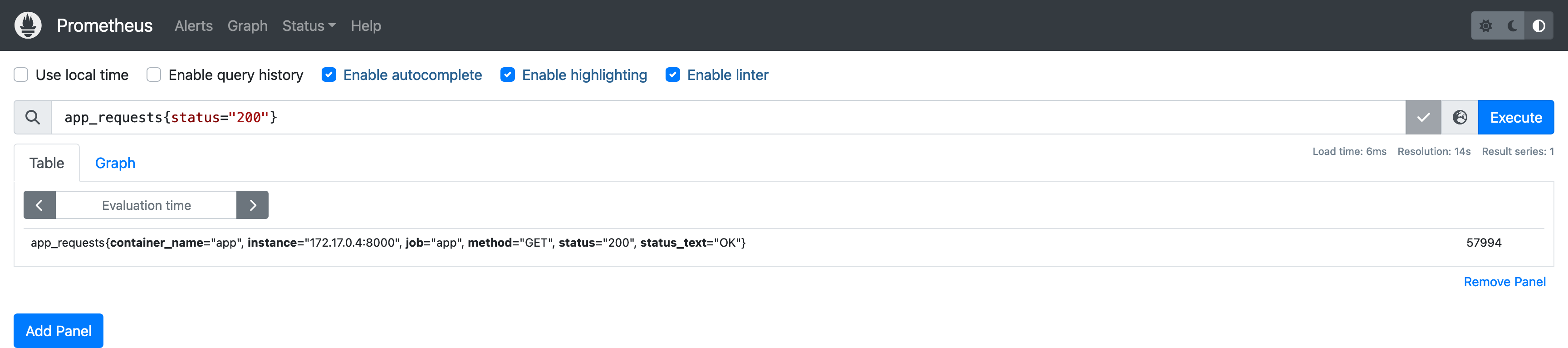
新的查询语句中加入了 标签选择器 过滤出 status 标签为 200 的指标序列。查询中可以使用零个或多个标签选择器,除了相等 =,PromQL 还支持多种标签匹配操作符:
- = : 完全匹配
- != : 完全不匹配
- =~ : 正则匹配,例如
mountpoint=~"^/run/.+" - !~ : 正则不匹配
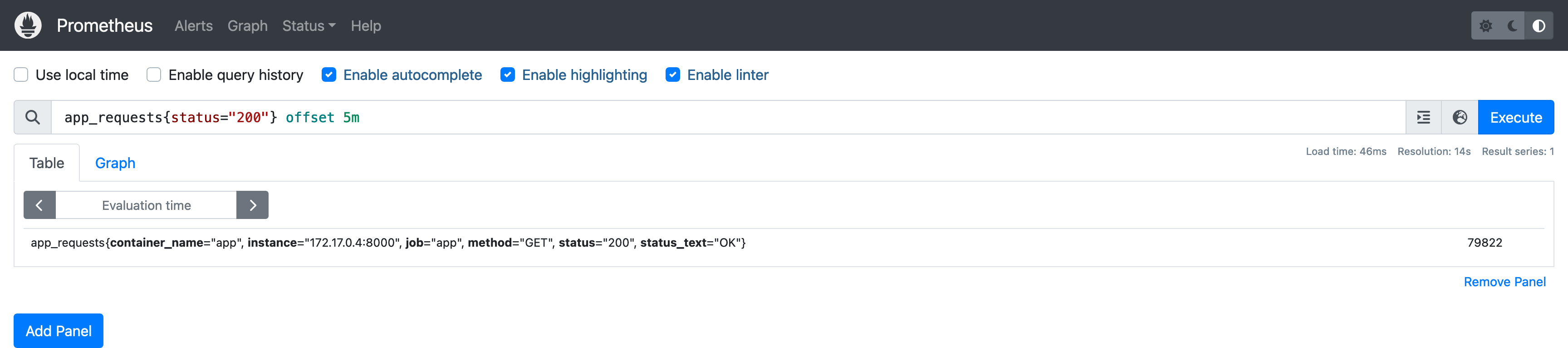
这个查询返回的是 当前时间点 的值,如果想要查看历史数据可以使用 offset 关键字,例如查看 5 分钟前的数据:
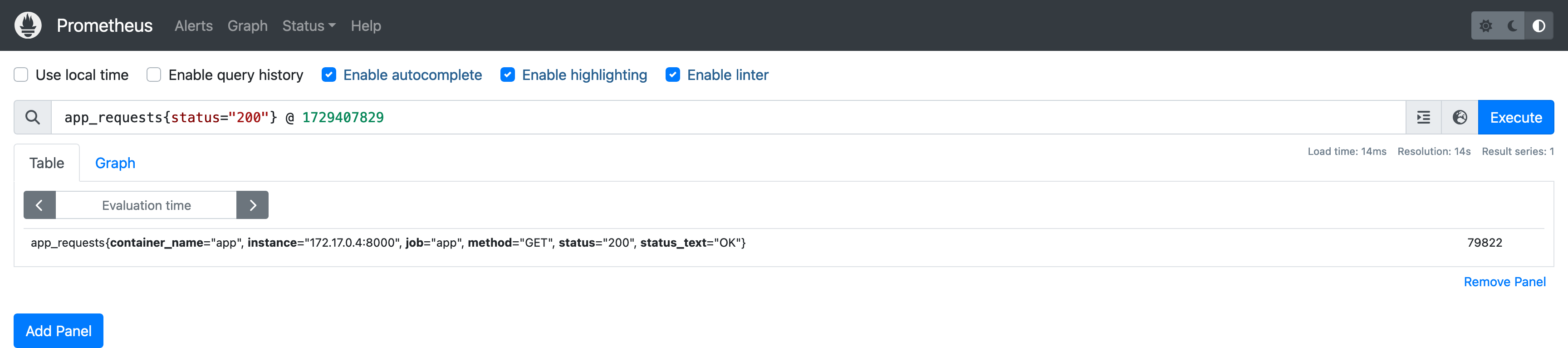
查看某个时间点的数据可以使用 @ 操作符:
以上都是针对某一个时间点的查询,查询结果称为 *瞬时向量(Instant Vector)*。
想要查询一段时间内的指标数据,可以在查询语句末尾加上时间范围:
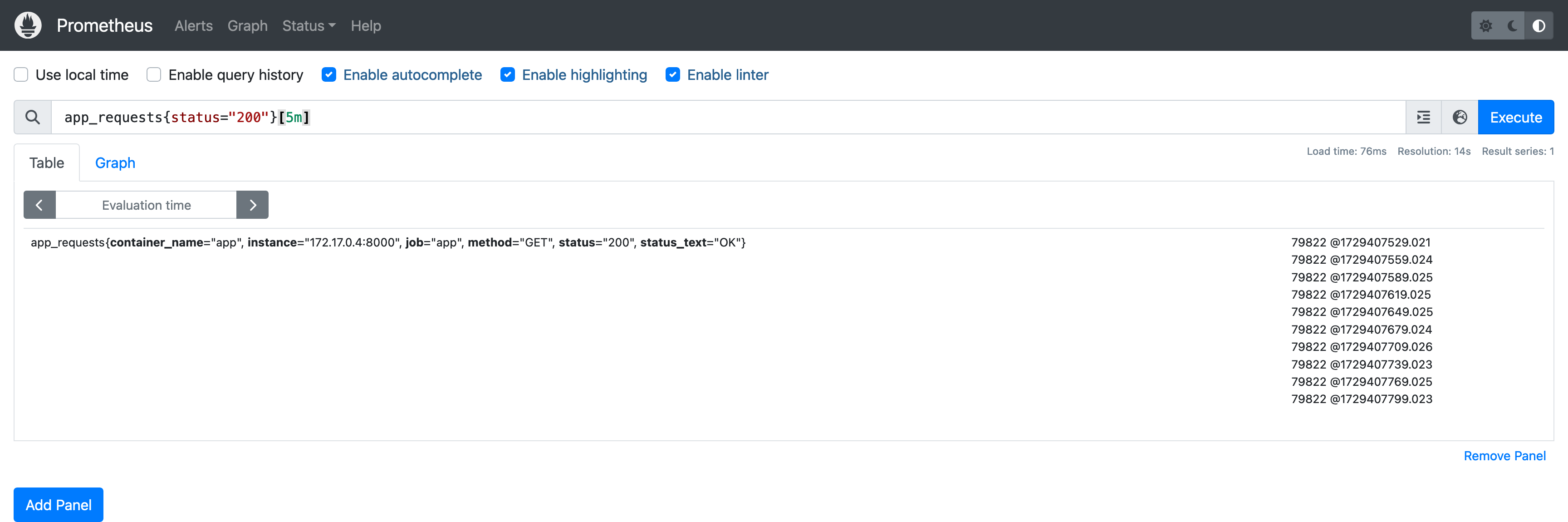
查询结果包含了 5 分钟内抓取到的所有指标值,这种查询结果称为 *范围向量(Range Vector)*,即包含一段时间内的所有时间点的值。
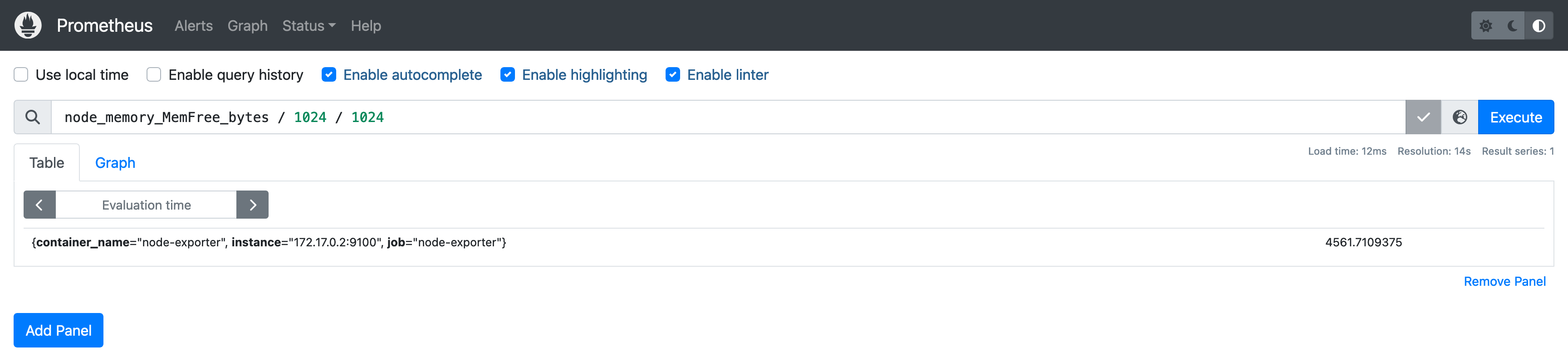
PromQL 支持对 瞬时向量 进行运算,比如将 node_memory_MemFree_bytes 指标转换为更易读的 MB 单位:
除了和标量(Scalar)进行运算,PromQL 还支持指标与指标之间的运算,比如可以通过 app_request_duration_seconds_sum 和 app_request_duration_seconds_count 指标计算出请求平均响应时间,这两个指标都是由 Histogram 自动生成的,分别表示样本值总和、样本值数量:
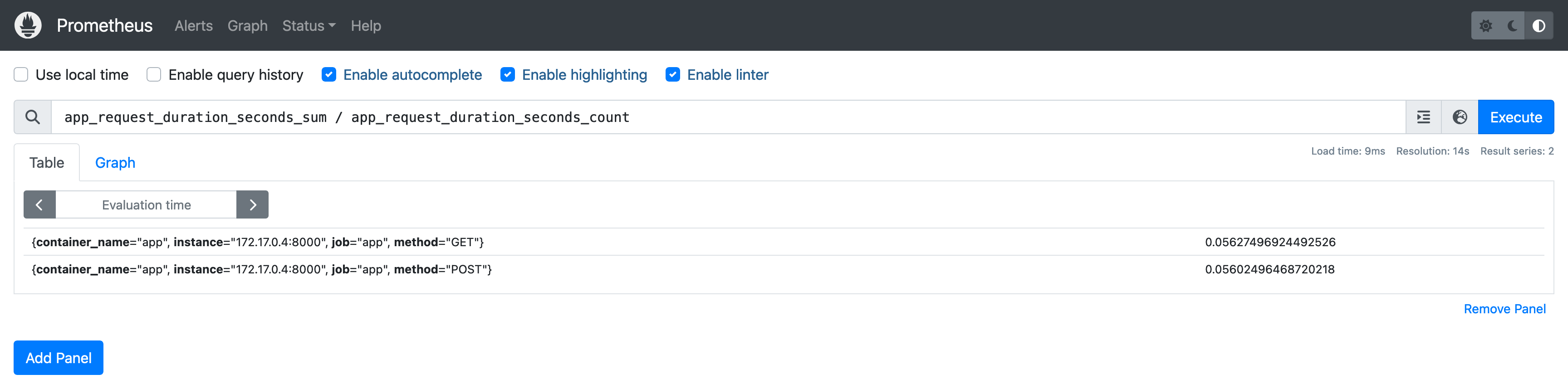
Prometheus 会将参与运算的指标序列进行标签匹配,查询结果中的每一条记录都是由两条具有完全相同标签集合的指标序列计算得到的。
PromQL 还支持聚合运算,以 node_cpu_seconds_total 指标为例,它提供了每个 CPU 核的累计使用时间:
1 | node_cpu_seconds_total{cpu="0", mode="idle"} 89193.3 |
如果我们想查询系统(system)总的 CPU 使用时间,可以使用 sum 函数进行聚合运算:
1 | sum(node_cpu_seconds_total{mode="system"}) |
你可能已经发现了输入框底下的 Graph 按钮,Prometheus 控制台内置了一个图表绘制界面,可以帮助我们更直观的查看指标数据:
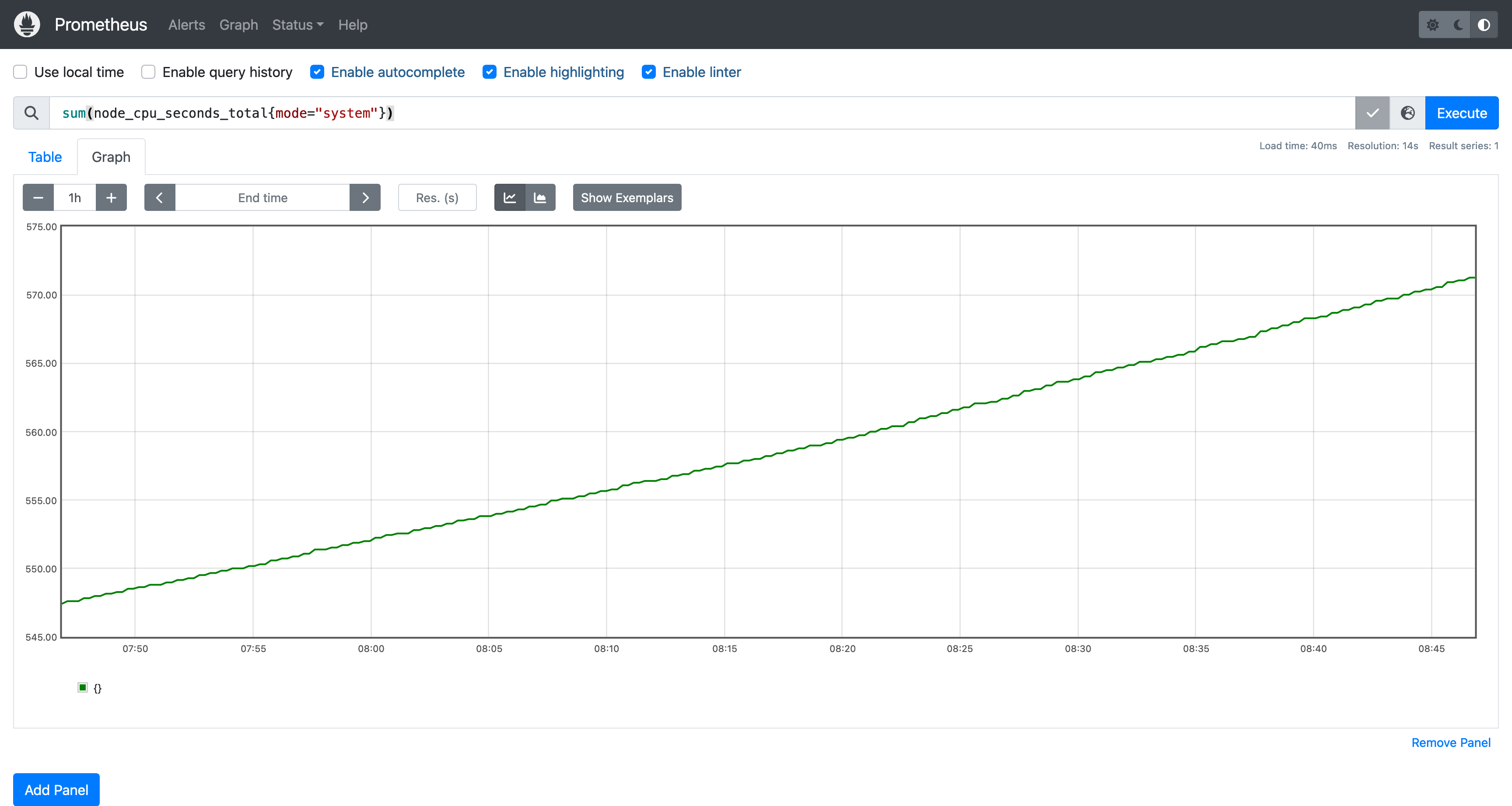
从图表中不难猜到 node_cpu_seconds_total 是一个 Counter 类型指标,因为它只会线性增长。对于这个指标而言,我们想要知道值变化情况而不是它的累计值,比如某个时间点 CPU 使用率飙升时,我们希望能够在图表上看到这个变化,这时候就需要使用 rate 函数:
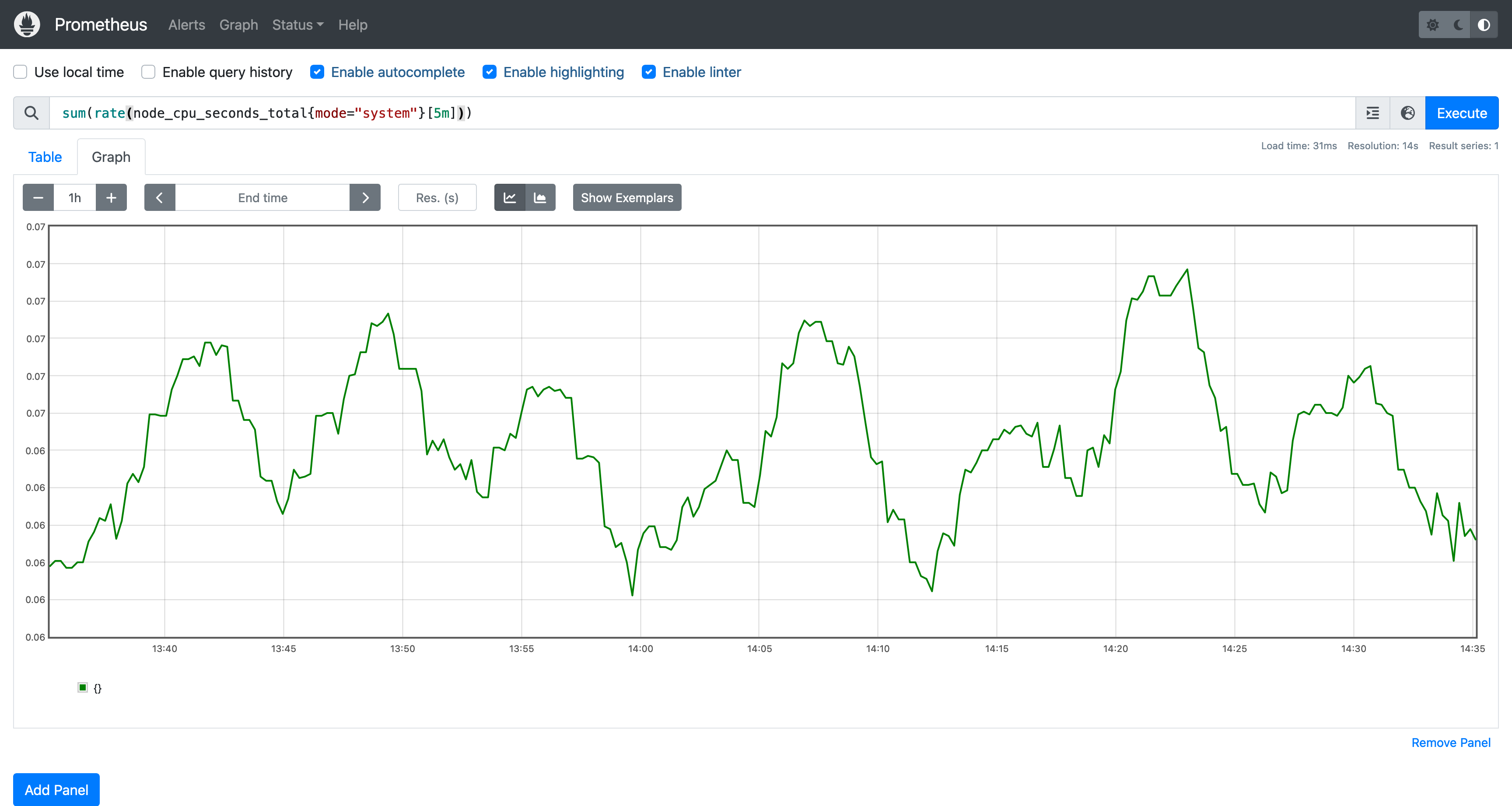
这个图表反映的是 CPU 使用率的 变化情况,rate 函数的作用是计算 范围向量 的增长速率,举个例子:指标序列在 T1 时刻值为 100,在 T2 时值为 120,rate 函数返回的是增长量 20 除以 T1 到 T2 的 间隔秒数。rate 函数另一个比较常见的场景是计算服务的每秒请求数(QPS)。
本文对 PromQL 的介绍就到这里,PromQL 是一门简洁而又功能强大的查询语言,想要掌握 Prometheus,PromQL 是必不可少的一部分。更多 PromQL 查询案例可以到 PromLabs 查看。