在 上一篇文章 中我们探讨了如何使用 Prometheus Adapter 与 HPA 结合来解决生产者 - 消费者模型中由于消费者处理能力不足导致生产者积压的问题。在这个过程中我们了解了 Metrics API 的概念以及如何在 HPA 中使用自定义指标和外部指标来实现更灵活更贴合业务的自动扩容策略。
虽然这个方案适合大多数场景但实施起来并不那么容易,主要原因是依赖 Prometheus,这意味着在集群中需要部署 Prometheus,业务也需要进行指标的埋点,这对于一些小型项目来说可能会增加不必要的复杂度,更不用说那些年代久远的项目了。今天我们来介绍一种更加轻量级的自动扩容方案:KEAD (Kubernetes Event-driven Autoscaling)。
KEDA 提供了一种基于事件驱动的自动扩容方案,KEDA 支持丰富的 事件来源,例如:ActiveMQ 队列长度、Redis List 长度、MySQL 查询结果等。KEDA 会直接访问这些事件源无需额外的指标采集工作,这对于一些没有指标采集需求的项目来说是非常友好的。接下来我们还是基于上篇文章的生产者 - 消费者场景,来看看如何使用 KEDA 来实现自动扩容。
安装 KEDA
KEDA 提供了 Helm Chart,通过简单的命令即可安装 KEDA 到集群中:
1 | $ helm repo add kedacore https://kedacore.github.io/charts |
安装完成后可以通过以下命令查看 KEDA 的状态:
1 | $ kubectl get po -n keda |
keda-operator 是核心组件,它负责对用户提交的 CRD 进行处理;keda-operator-metrics-apiserver 是一个 Metrics API 适配器,作用和 Prometheus Adapter 相似,负责将事件源的数据转换为 Metrics API 指标。下面我们来看看如何使用 KEDA。
ScaledObject
ScaledObject 是 KEDA 的核心资源,用于定义扩容目标以及事件源和触发规则:
1 | apiVersion: keda.sh/v1alpha1 |
我们需要扩容的目标对象是 Deployment/hpa-app-consumer,业务使用的是 Redis 列表作为消息队列所以我们选择 Redis Lists 来作为触发事件源。规则中指定了 Redis 连接地址以及列表 key 名称,当列表长度 > 100 时触发,详细的的配置可以参考文档。使用 kubectl 提交 ScaledObject 后运行 hpa-example 中的测试用例向生产者发送请求:
hpa-example部署方式参考 k8s: 基于消息队列长度自动扩容业务 Pods (HPA)
1 | $ helm test hpa-app --timeout=30m |
运行完毕后查看监控数据:
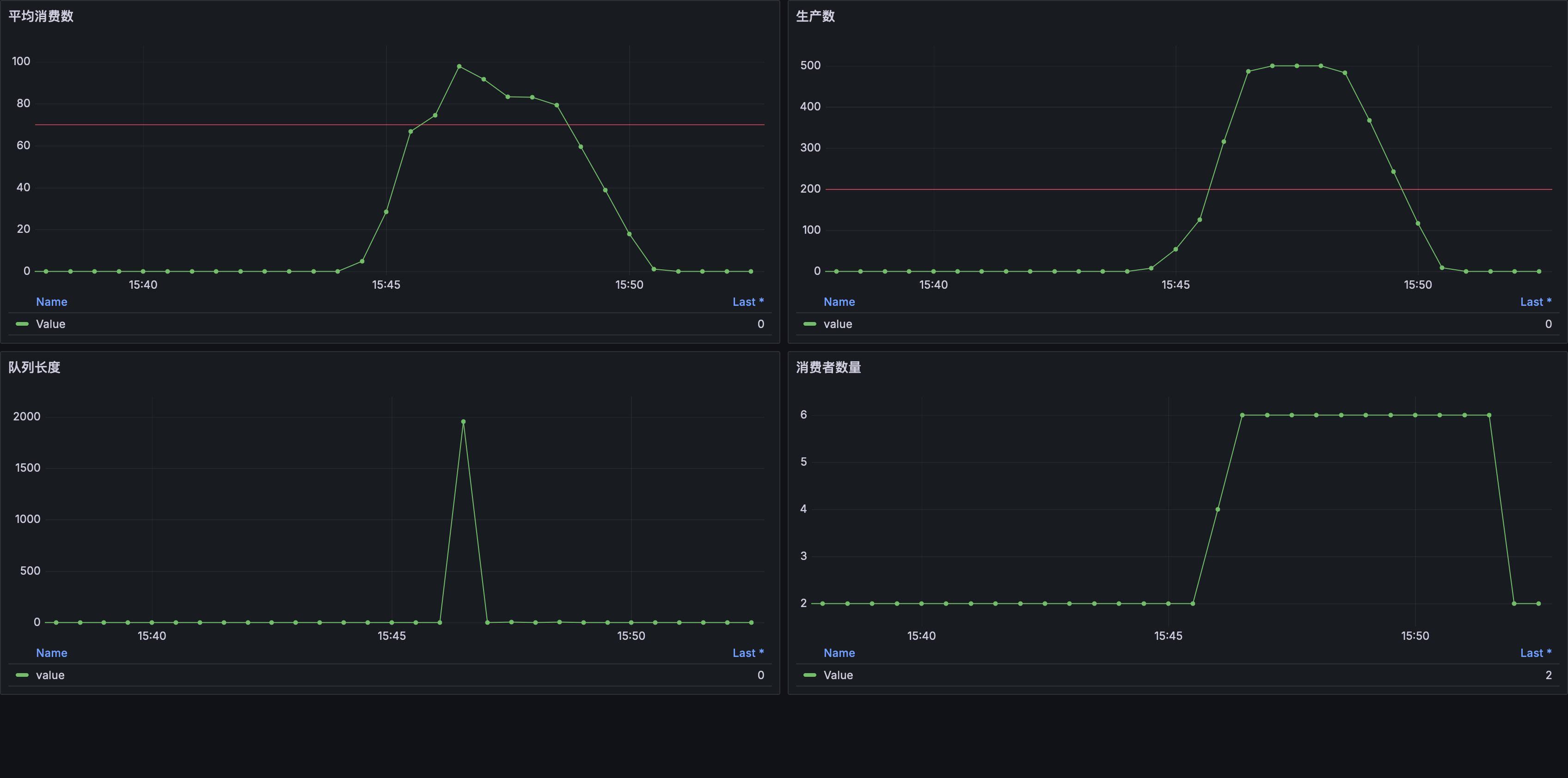
可以看到当 队列长度 超过 100 后 消费者数量 开始增加从而避免了消息积压。
工作原理
当我们创建ScaledObject 后 KEDA 会同步创建一个 HPA 对象:
1 | apiVersion: autoscaling/v2 |
接下来的流程我们就很熟悉了,HPA 使用外部指标 s0-redis-hpa-app 驱动,而这个指标是 operator-metrics-apiserver 根据事件源生成的,相比起上篇文章中介绍的 Prometheus Adapter 方案,KEDA 简化了指标采集和外部指标的配置。
ScaledJob
ScaledJob 是 KEDA 的另一个核心资源,无论是上面介绍的 ScaledObject 亦或者是 Prometheus Adapter 方案,最终还是依靠 HPA 来完成扩容,而 HPA 针对的是 Deployment、StatefulSet 这类长期运行的工作负载,但有些场景下我们希望仅在需要的时候才创建对应的 Kubernetes 资源,这时候就可以使用 ScaledJob,和 ScaledObject 的区别在于当需要扩容时 ScaleJob 会创建适合短期运行的 Job 资源,运行结束后会自动删除。
1 | kind: ScaledJob |
和 ScaledObject 类似 ScaledJob 也需要指定触发规则,但无需指定扩容目标而是通过 jobTargetRef 指定 Job 模板。需要注意的是,KEDA 不会对 Job 进行「缩容」操作,需要在 Job 模板中设置 activeDeadlineSeconds 来控制 Job 的生命周期,以上面的配置为例,当 Job 运行时间超过 600 秒后会被 Kubernetes 终止并在 300 秒后删除,此时如果队列里还有消息 KEDA 会再次创建 Job 直到触发规则不满足。