HPA (Horizontal Pod Autoscaler) 是 Kubernetes 提供的一种自动扩容机制,它可以根据指定的指标自动调整 Pods 的副本数量以满足应用的负载需求。在 1.6 版本之前,HPA 只支持基于 CPU 和内存的指标,即根据 Pod 的 CPU 和内存使用情况来进行扩容,但这种方式并不能全面反映应用的实际负载情况,例如,一个 Web 应用(I/O 密集型)可能更多地依赖磁盘或网络带宽,而这些资源的使用情况可能不会直接反映在 CPU 或内存指标上。因此在 HPA v2 中新增了对 Metrics API 的支持,允许使用者通过外部监控系统提供的指标驱动 HPA 扩容。下面我们将探讨如何使用 HPA 结合 Metrics API 来解决一类常见场景:生产者-消费者模型中,生产者生产的消息速度大于消费者的处理速度导致消息积压。为了更好的演示这里准备了一个小程序来模拟这种场景,包含两个模块:
生产者 (Producer):接收 HTTP 请求后向队列中写入消息,提供以下 Prometheus 指标:
hpa_app_queue_length:Gauge类型,队列长度hpa_app_produce_count:Counter类型,生产消息数量
消费者 (Consumer):从队列中读取消息并处理 (sleep 10ms),提供以下 Prometheus 指标:
hpa_app_consume_count:Counter类型,消费消息数量
首先在集群中部署实验环境,需要注意集群需要部署 Prometheus Operator,具体方法可以参考 文档 这里不再赘述:
1 | git clone https://github.com/yxwuxuanl/hpa-example.git |
完成以上步骤后会在集群中部署一个生产者和两个消费者副本并且创建 Prometheus 采集规则,等到所有 Pod 都启动后运行 helm test hpa-app --timeout=30m 命令执行测试用例向生产者发送请求,测试启动后 1 分钟内会达到 100 QPS,随后会在 1 分钟内上升到 500 QPS 并持续 2 分钟,这个流量曲线符合业务中突发流量的特征:
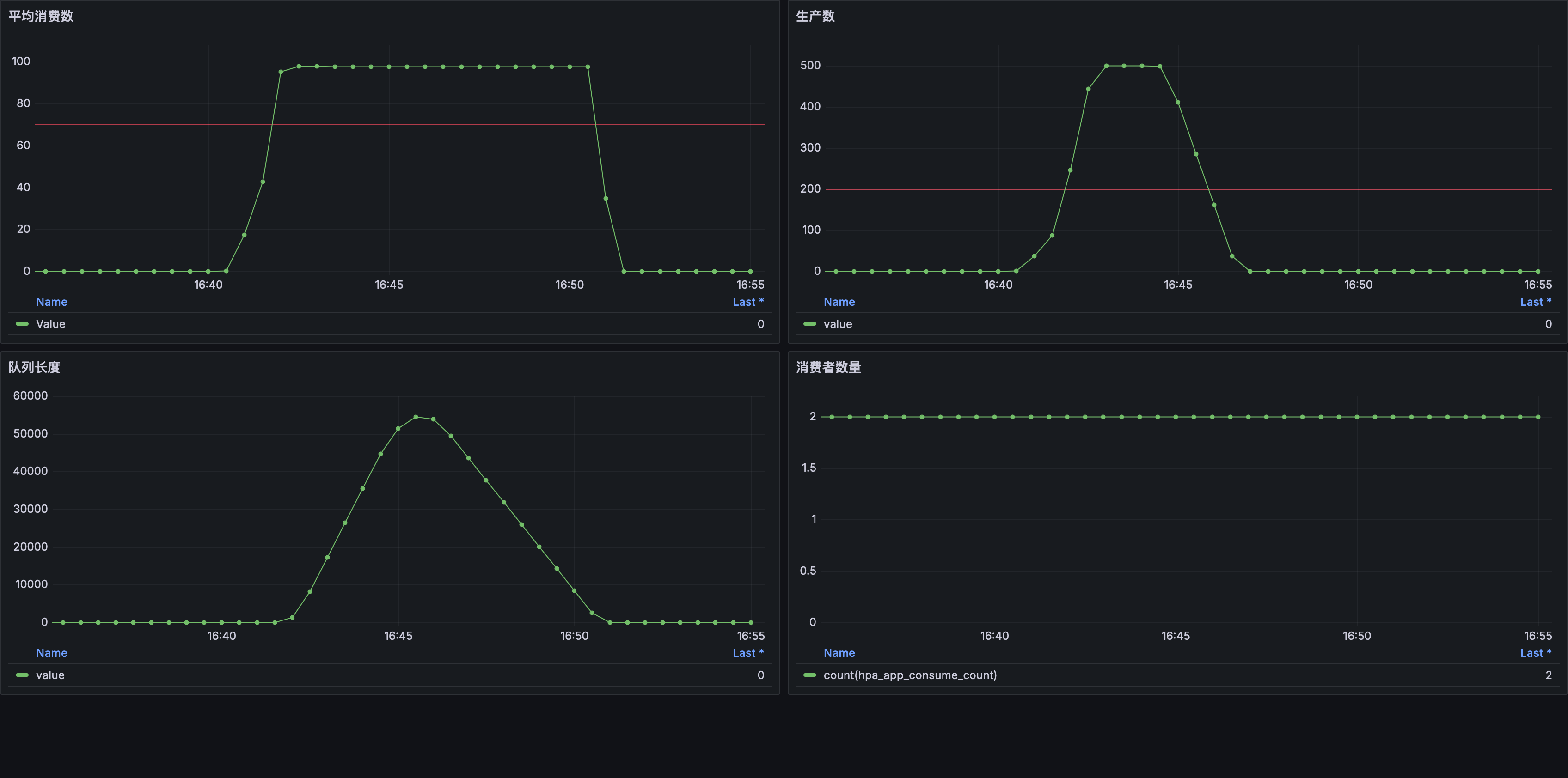
消费者处理一条消息需要 10ms 因此最大消费速度为 100 条/秒,部署了 2 个消费者副本的情况下队列最大消费速度为 200 条/秒,当 消息生产数量 超过 200 警戒线后 队列消息数量 快速增长并持续了一段时间,这显然不是我们想要的结果,接下来我们将使用 HPA 来解决这个问题。
Metrics API
在进入正题之前先来介绍一下上面提到的 Metrics API,顾名思义 Metrics API 的作用是给 Kubernetes 提供指标,HPA 控制器和 kubectl top 命令都会用到,具体来说 Metrics API 包含两个部分:
custom.metrics.k8s.io 用于提供 Kubernetes 对象的 自定义指标,例如:某个 Pod 对象的数据库连接数、某个 Service 对象的请求数等,这些指标由用户的监控系统提供,但必须要关联 Kubernetes 中的对象。
external.metrics.k8s.io 用于提供 Kubernetes 对象无关的 外部指标,例如:消息队列系统的消息数量、云厂商提供的负载均衡器的请求数等。
Kubernetes 仅提供了 Metrics API 的定义,因此需要 Prometheus Adapter 作为适配器来提供数据,它可以将 Metrics API 请求转换为 Prometheus 查询并将查询结果转换为 Metrics API 支持的数据结构。Helm Chart 中已经包含了 Prometheus Adapter,使用 helm upgrade 命令更新 Release:
1 | helm upgrade hpa-app . -n default \ |
将
<PROMETHEUS_URL>替换为 Prometheus 的集群地址
部署完成后会创建一个 API Service 对象来「申领」Metrics API 的请求,我们可以通过 /apis/custom.metrics.k8s.io/v1beta1 检查 Metrics API:
1 | kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq |
custom.metrics.k8s.io API 组下有两个资源,这是由 Prometheus Adapter 提供的,稍后会介绍这个过程。这里重点关注 pods/hpa_app_consume_per_second,pods 表示 Kubernetes 的 Pods 资源,hpa_app_consume_per_second 是自定义指标的名称,从名字可以看出这个自定义指标是由消费者的 hpa_app_consume_count 指标转换而来。我们可以通过 URL 设计规范 进一步查看数据:
1 | kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/hpa_app_consume_per_second | jq |
这个 URL 的含义是获取 default 命名空间下所有 pods 对象的 hpa_app_consume_per_second 自定义指标,返回结果中包含自定义指标关联的对象describedObject 以及指标值 `value。接下来我们来看如何在 HPA 中使用自定义指标。
使用自定义指标驱动 HPA
1 | apiVersion: autoscaling/v2 # 使用 HPA v2 |
这个 HPA 对象扩缩容目标是 Deployment/hpa-app-consumer,指标来源于它所控制的 Pods 对象关联的 hpa_app_consume_per_second 自定义指标,目标值为 70,目标值类型为 平均值。当消费者 Pods 的消费平均值 > 70 条/秒 时 HPA 会进行扩容操作并且最多允许扩容到 6 个副本。创建好 HPA 再次运行压测脚本:
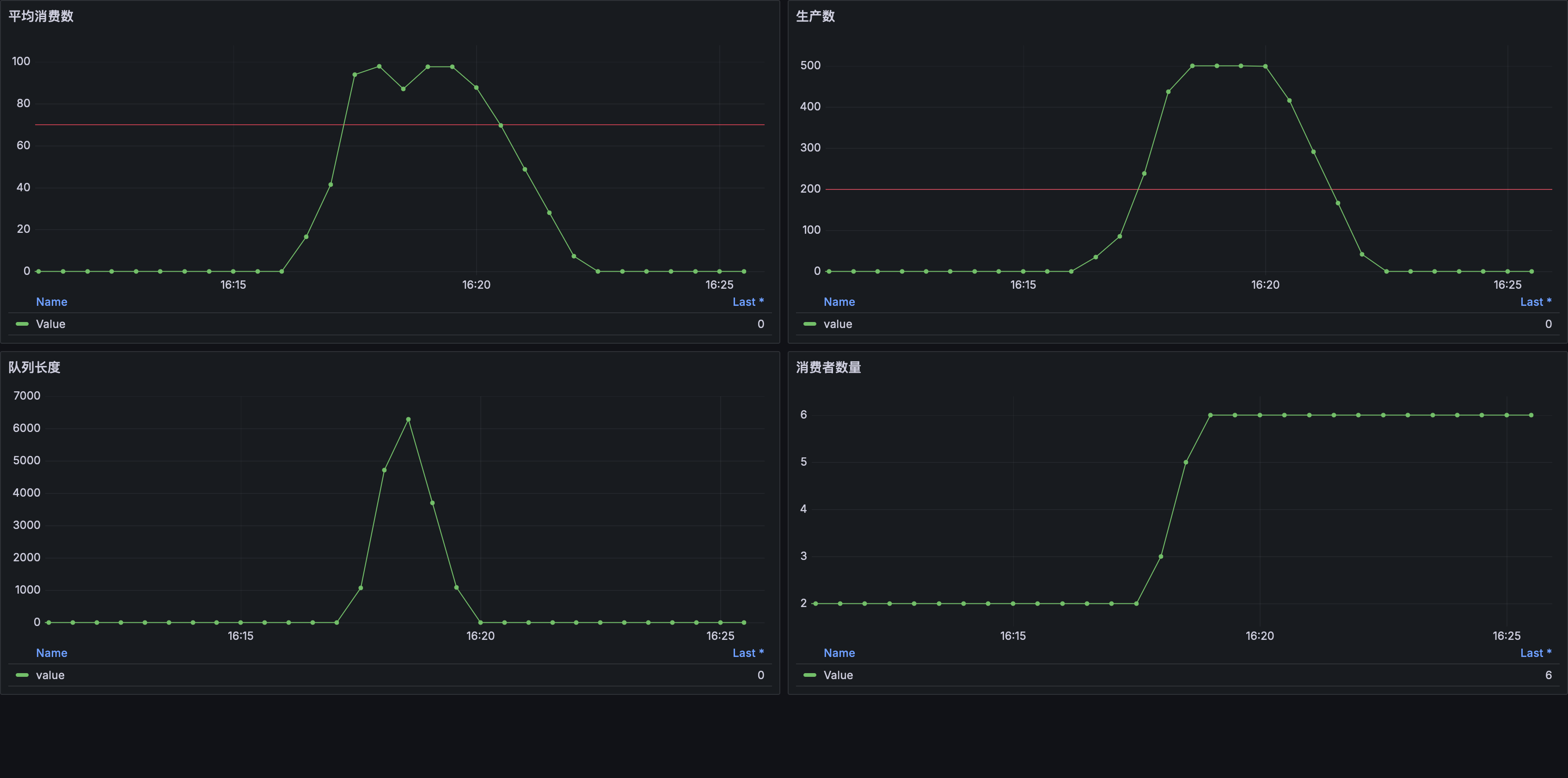
可以看到这次情况好很多,当 平均消费数 超过告警线 (HPA 目标值) 后 HPA 如预期一样开始扩容消费者副本,虽然还是发生了消息积压但很快就被消费完。
Prometheus Adapter 配置
通过上面的例子我们已经初步领略了 HPA + 自定义指标的「威力」,在继续介绍外部指标之前我们先来了解一下自定义指标是如何配置的:
1 | # deploy/values.yaml |
rules.custom 数组中每个元素都表示一个自定义指标的生成规则,官方文档 中将这个过程分为四个步骤,对应配置中的四个字段:
seriesQuery: 过滤 Prometheus 指标,这里使用消费数指标作为来源,也可以写成{__name__="hpa_app_consume_count"}。resources: 关联 Kubernetes 对象和 Prometheus 指标。也就是将特定 Kubernetes 对象的名称转换为 Prometheus 指标的标签值用于查询。name: 指定自定义指标名称。metricsQuery: 指定 Prometheus 查询语句,<<.GroupBy>>、<<.Series>>和<<.LabelMatchers>>三个占位符分别表示分组、指标序列和标签匹配器,这些占位符会在运行时被替换为实际的值。
resources 字段是配置的核心,它决定了 HPA 能否正确获取指定 Kubernetes 对象的指标。resources.overrides 允许我们对两者进行映射操作,Key 表示 Prometheus 指标的标签名称,Value 表示标签值来源,配置 resources.overrides.pod: {resource: pod} 的含义是 Prometheus 指标的 pod 标签值映射到 Kubernetes 的 pod 资源,namespace 标签同理。Prometheus Adapter 是如何找到自定义指标对应的 Pod 对象的呢?我们先来看 HPA 控制器是如何查询自定义指标的:
1 | { |
从 api-server 的审计日志中可以找到 HPA 控制器的查询请求,从 objectRef.name 字段可以看出 HPA 控制器并没有指定要查询的具体 Pod 名称,而是使用了 labelSelector 参数来过滤 Pods,这个参数来自于扩缩容目标的 spec.selector 字段。Prometheus Adapter 会使用 labelSelector 参数的标签选择器在集群中找出对应的 Pods 后将名称作为 pod 标签的值,最终 Prometheus Adapter 会生成下面的 PromQL 查询语句:
1 | sum by (pod) (rate(hpa_app_consume_count{namespace="default",pod=~"hpa-app-consumer-6cd8cdb47b-ddd9g|hpa-app-consumer-6cd8cdb47b-nbqnk"}[30s])) |
使用外部指标驱动 HPA
了解完 Prometheus Adapter 配置后我们再回头看上面的图表,虽然 HPA 触发了扩容但消息积压的情况还是持续了一小段时间,这是因为在 HPA 中使用的是 平均值 作为目标值,因此当增加了新的副本后 HPA 需要再次计算指标值,超过目标值后才会继续下一轮扩容,这个过程会导致一定的延迟。虽然可以将 HPA 目标值调低让 HPA 尽早扩容来缓解这个问题,但这样可能会导致频繁触发扩容。最理想的解决方案是 HPA 能根据队列里的消息数量「一步到位」进行扩容,这需要使用外部指标来实现:
1 | prometheus-adapter: |
rules.external 数组中每个元素表示一个外部指标的生成规则,这次我们使用 hpa_app_queue_length 指标,这个指标反映的是队列长度与具体的 Pod 对象无关,因此在 resources 字段中只需要映射 namespace 标签即可。在 metricsQuery 中我们使用了 queue_name 标签来分组避免多个队列的指标混在一起。同样的我们可以使用kubectl get 命令查看外部指标:
1 | kubectl get --raw /apis/external.metrics.k8s.io/v1beta1/namespaces/default/hpa_app_queue_length | jq |
配置中省略了 name 字段,Prometheus Adapter 会使用 seriesQuery 指定的指标名称作为自定义指标名称。接下来我们修改 HPA 配置:
1 | apiVersion: autoscaling/v2 # 使用 HPA v2 |
这次我们将 type 字段设置为 External 来使用外部指标,需要注意的是由于外部指标不与 Kubernetes 对象进行关联,我们需要使用 external.metric.selector 来选择正确的外部指标。目标值也不再使用平均值,当队列长度超过 100 时 HPA 会进行扩容。更新 HPA 对象后再次运行压测:
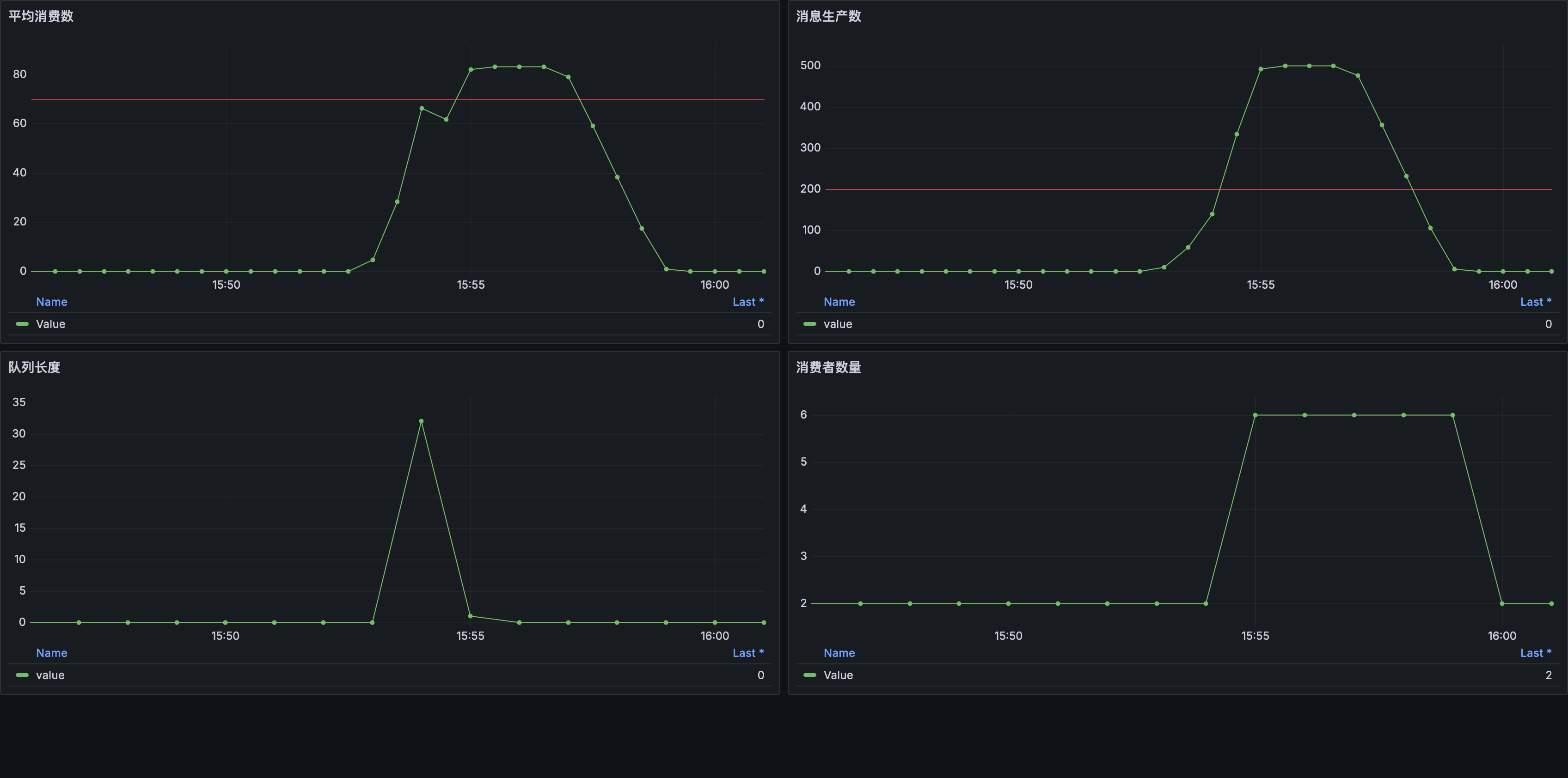
可以看到当 队列长度 超过目标值时 HPA 控制器开始扩容,但这次并不是逐步增加而是直接扩容到 6 个副本,积压的消息很快就被消费完毕,很显然这种方式更适合于生产者-消费者模型中的场景。