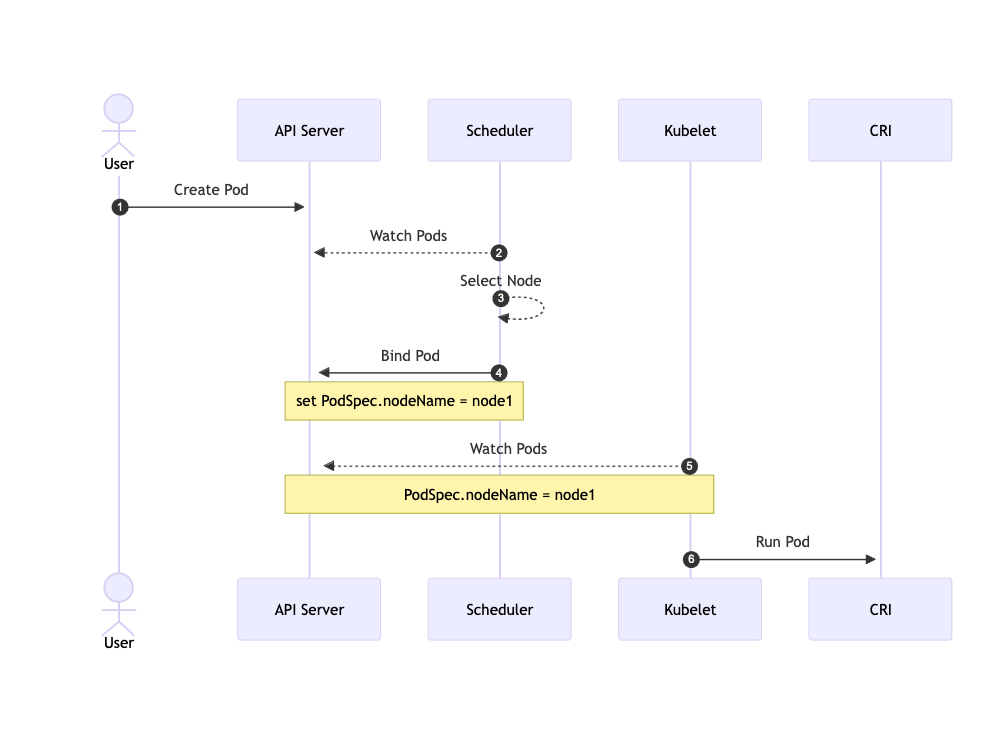
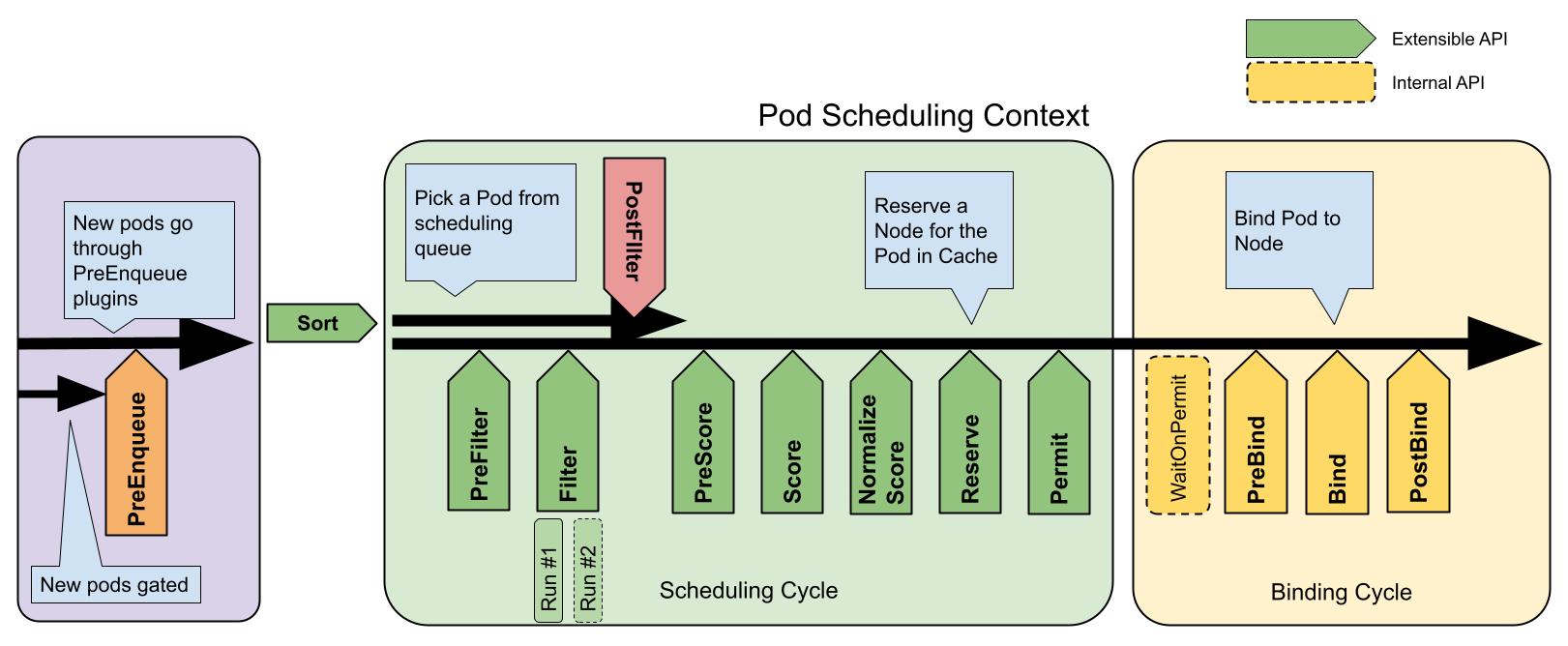
在 Kubernetes 中,调度是指将 Pod 放置到合适的节点上,以便对应节点上的 Kubelet 能够运行这些 Pod。调度器通过 Kubernetes 的监测(Watch)机制来发现集群中新创建且尚未被调度到节点上的 Pod。 调度器会将所发现的每一个未调度的 Pod 调度到一个合适的节点上来运行。调度器会依据下文的调度原则来做出调度选择。
调度器的工作流程可以总结为以下步骤:
监测未被调度到节点上的 Pod
选择合适的节点
将 Pod 调度到节点上
虽然大概知道了调度器的工作流程,但有两个小问题需要解答:如何定义未被调度到节点上的 Pod?如何将 Pod 调度到节点上?带着这两个问题来看一个「MVP」调度器:random-scheduler。顾名思义这个调度器会将 Pod 随机调度到节点上,虽然不具有实际意义但它能让我们更直观地了解调度器的工作流程:
$ curl http://blackbox-exporter:9115/probe?module=http_2xx&target=lin2ur.cn ... # HELP probe_duration_seconds Returns how long the probe took to complete in seconds # TYPE probe_duration_seconds gauge probe_duration_seconds 0.124378116 # HELP probe_http_duration_seconds Duration of http request by phase, summed over all redirects # TYPE probe_http_duration_seconds gauge probe_http_duration_seconds{phase="connect"} 0.029487528 probe_http_duration_seconds{phase="processing"} 0.029606199 probe_http_duration_seconds{phase="resolve"} 0.016701177999999997 probe_http_duration_seconds{phase="tls"} 0.032871766 probe_http_duration_seconds{phase="transfer"} 0.014863664 ...
// Code is the Status code/type which is returned from plugins. type Code int
const ( // Success means that plugin ran correctly and found pod schedulable. // NOTE: A nil status is also considered as "Success". Success Code = iota // Error is one of the failures, used for internal plugin errors, unexpected input, etc. // Plugin shouldn't return this code for expected failures, like Unschedulable. // Since it's the unexpected failure, the scheduling queue registers the pod without unschedulable plugins. // Meaning, the Pod will be requeued to activeQ/backoffQ soon. Error // Unschedulable is one of the failures, used when a plugin finds a pod unschedulable. // If it's returned from PreFilter or Filter, the scheduler might attempt to // run other postFilter plugins like preemption to get this pod scheduled. // Use UnschedulableAndUnresolvable to make the scheduler skipping other postFilter plugins. // The accompanying status message should explain why the pod is unschedulable. // // We regard the backoff as a penalty of wasting the scheduling cycle. // When the scheduling queue requeues Pods, which was rejected with Unschedulable in the last scheduling, // the Pod goes through backoff. Unschedulable // ... )
// NewStatus makes a Status out of the given arguments and returns its pointer. funcNewStatus(code Code, reasons ...string) *Status {}
type ScorePlugin interface { Plugin // Score is called on each filtered node. It must return success and an integer // indicating the rank of the node. All scoring plugins must return success or // the pod will be rejected. Score(ctx context.Context, state *CycleState, p *v1.Pod, nodeName string) (int64, *Status) // ... }
从日志中可以看出 raspberrypi 节点得到了最高的分数,我们来看看 Pod 最终调度到哪个节点上:
1 2 3
$ kubectl get po -n network-scheduler -l job-name=network-scheduler-7bjdk-jz7l5 -o wide NAME READY STATUS RESTARTS AGE IP NODE network-scheduler-7bjdk-jz7l5 0/1 Completed 0 37s 10.42.2.86 macmini
Pod 并没有如预期的那样调度到得分最高的 raspberrypi 节点上,这是因为 macmini 节点的可用 CPU 和内存资源比 raspberrypi 节点多,即使 NetworkSpeed 插件给 raspberrypi 节点打了最高分,但最终得分需要综合所有打分插件的分数,因此调度器最终选择了 macmini 节点。
调整插件的权重后创建新的 Pod 调度器就如预期那样将 Pod 调度到 raspberrypi 节点上了:
1 2 3
$ kubectl get po -n network-scheduler -l job-name=network-scheduler-nvbz2-pg46z -o wide NAME READY STATUS RESTARTS AGE IP NODE network-scheduler-nvbz2-pg46z 0/1 Completed 0 7s 10.42.2.102 raspberrypi
调整默认调度器行为
除了扩展调度插件外,我们也可以对内置插件的配置进行调整来改变调度器的行为,例如以下场景:假设集群有 4 个 4C8G 的节点,现有 20 个 Pod 需要调度,每个 Pod 需要 0.5 核 CPU 以及 1G 内存,我们知道调度器会尽量平衡各个节点的资源占用,因此这 20 个 Pod 大概率会平分到 4 个节点上,每个节点上运行 5 个 Pod,剩余 2C3G 的可用资源。
这看起来很好所有 Pod 都能运行并且每个节点都剩余了一些资源,但如果此时有个需要 4核 CPU 的 Pod 需要运行那情况就会变得糟糕起来,即使整个集群还剩余 8核 CPU 这个 Pod 仍然无法被调度运行,因为没有能满足 CPU 需求的节点,这种现象我们称为资源碎片化。